 useok's blog
useok's blog

토픽
카프카에는 다양한 데이터가 들어갈 수 있는데, 그 데이터가 들어가는 공간을 토픽이라고 부름
토픽은 일반적인 AMQP(Advanced Message Queuing Protocol)와 다소 다르게 동작
카프카에서는 토픽을 여러개 생성할 수 있음
토픽은 데이터베이스의 테이블이나 파일시스템의 폴더와 유사한 성질을 가지고 있는데, 이 토픽에 프로듀서가 데이터를 넣게 되고, 컨슈머는 데이터를 가져감
하나의 토픽은 여러개의 파티션으로 구성될 수 있으며, 파티션을 늘릴 수는 있지만 줄일 수는 없음
하나의 파티션은 큐와같이 내부에 데이터가 파티션 끝에서부터 차곡차곡 쌓이게 됨
토픽에 카프카 컨슈머가 붙게되면 데이터를 가장 오래된 순서대로 가져가게 됨
더이상 데이터가 들어오지 않으면 컨슈머는 또 다른 데이터가 들어올 때까지 기다림
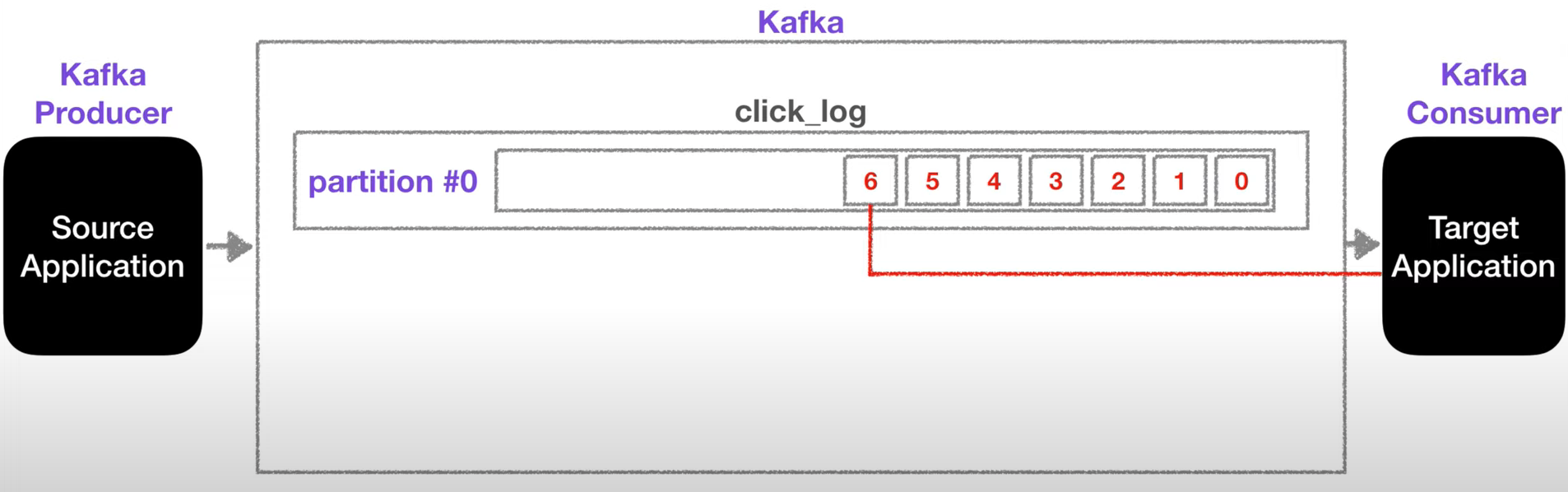
컨슈머가 토픽 내부의 파티션에서 데이터를 가져가더라도 데이터는 삭제되지 않고 파티션에 그대로 남음
이 파티션에 삭제되지 않고 남은 데이터는 새로운 컨슈머가 붙었을 때 다시 0번부터 가져가서 사용할 수 있음
다만, 컨슈머 그룹이 달라야하고 auto.offset.reset = earliest 로 설정되어 있어야 함
이렇게 사용할 경우, 동일 데이터에 대해 두 번 처리할 수 있는데, 이는 카프카를 사용하는 아주 중요한 이유로, 예를들어 클릭로그를 분석하고 시각화 하기 위해 엘라스틱서치에 데이터를 저장하고, 백업용도로 하둡에도 저장할 수 있음
토픽 내에 파티션이 두 개 이상인 경우
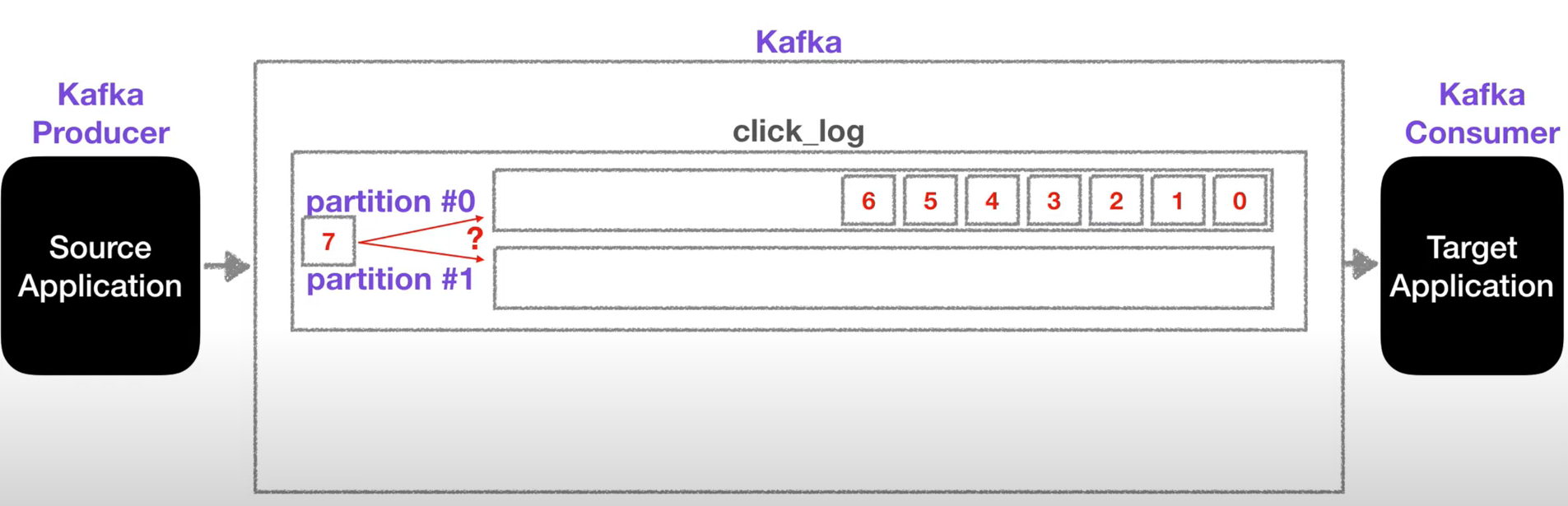
위 그림과 같이 7 데이터를 넣는데 파티션이 두 개인 경우, 어느 파티션에 들어가는지는 프로듀서가 데이터를 보낼 때 키를 지정해 특정 파티션에 넣을 수 있음
- 키가 null(키를 지정하지 않음)이고 기본 파티셔너를 사용할 경우, 라운드 로빈으로 할당
- 위 그림과 같은 경우 데이터는 파티션 1에 들어가고 다음 데이터는 파티션 0, 1,0,1,0 순서로 들어감
- 키가 있고, 기본 파티셔너를 사용할 경우, 키의 해시값을 구하고, 특정 파티션에 할당
파티션을 늘리면 컨슈머의 개수를 늘려서 데이터 처리를 분산시킬 수 있음
파티션의 데이터가 삭제되는 경우는 옵션에 따라 다름
- 레코드가 저장되는 최대 시간과 크기
- log.retention.ms : 최대 record 보존 시간
- log.retention.byte: 최대 record 보존 크기(byte)
이를 지정하게 되면 일정한 기간 혹은 용량 동안 데이터를 저장할 수 있고, 적절하게 데이터가 삭제될 수 있도록 설정 할 수 있음
참고 강의 : https://www.inflearn.com/course/아파치-카프카-입문/dashboard