useok's blog
useok's blog

아파치 카프카 개요
카프카를 본격적으로 공부하기 앞서 인프런의 “[데브원영] 아파치 카프카 for beginners” 강의를 통해 카프카 기본 지식을 습득 하고자 함
강의 링크 : https://www.inflearn.com/course/아파치-카프카-입문/dashboard
Before Kafka
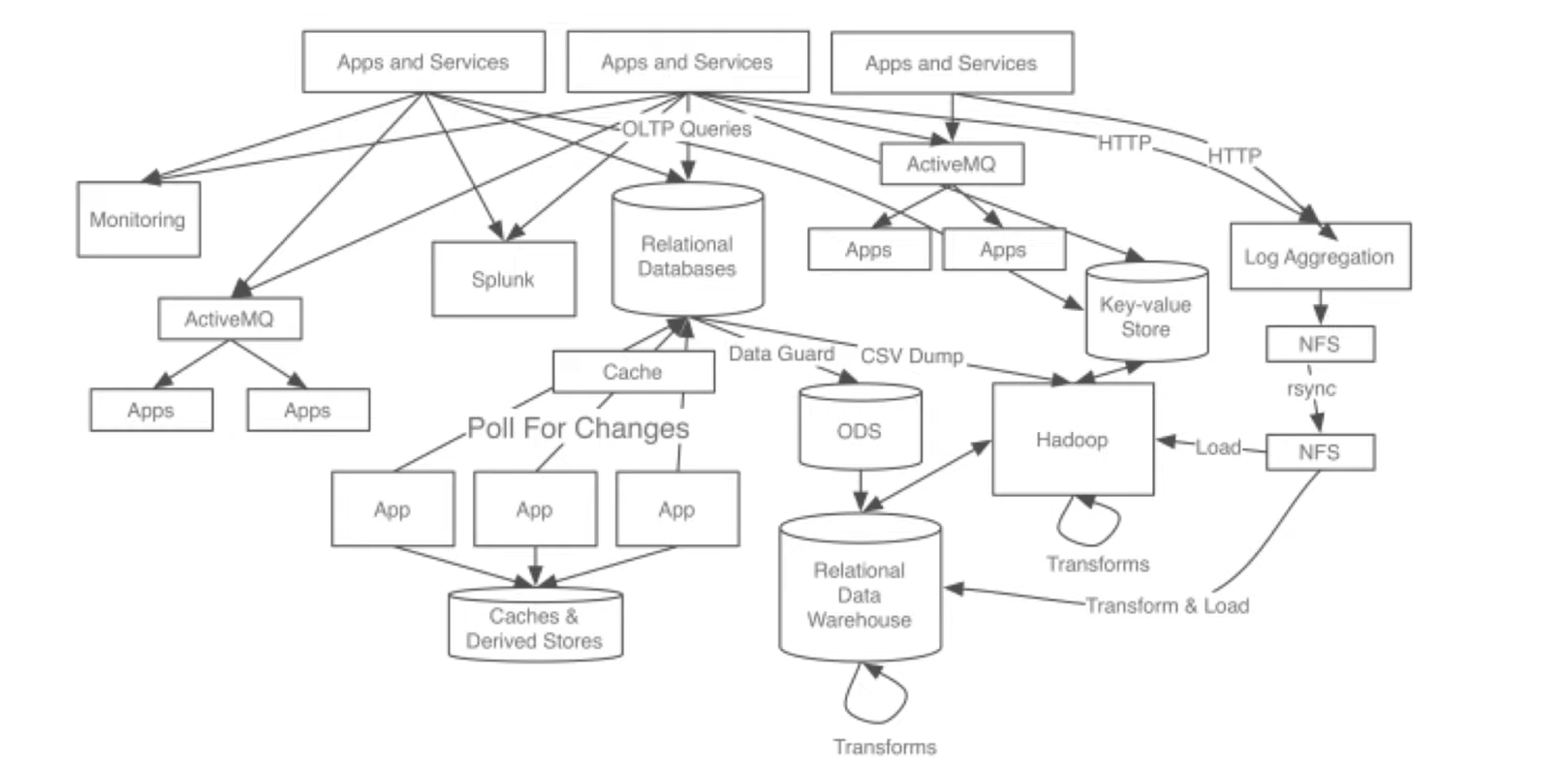
데이터를 전송하는 Source Application과 데이터를 전송받는 Target Application이 많아질수록 데이터를 전송하는 라인이 매우 복잡해짐
데이터 전송라인이 많아지면 배포와 장애에 대응하기 어렵고, 데이터를 전송할 때 프로토콜 포맷의 파편화가 심해짐
또한, 데이터의 포맷 내부에 변경사항이 있을 때 유지보수 하기가 매우 어려움
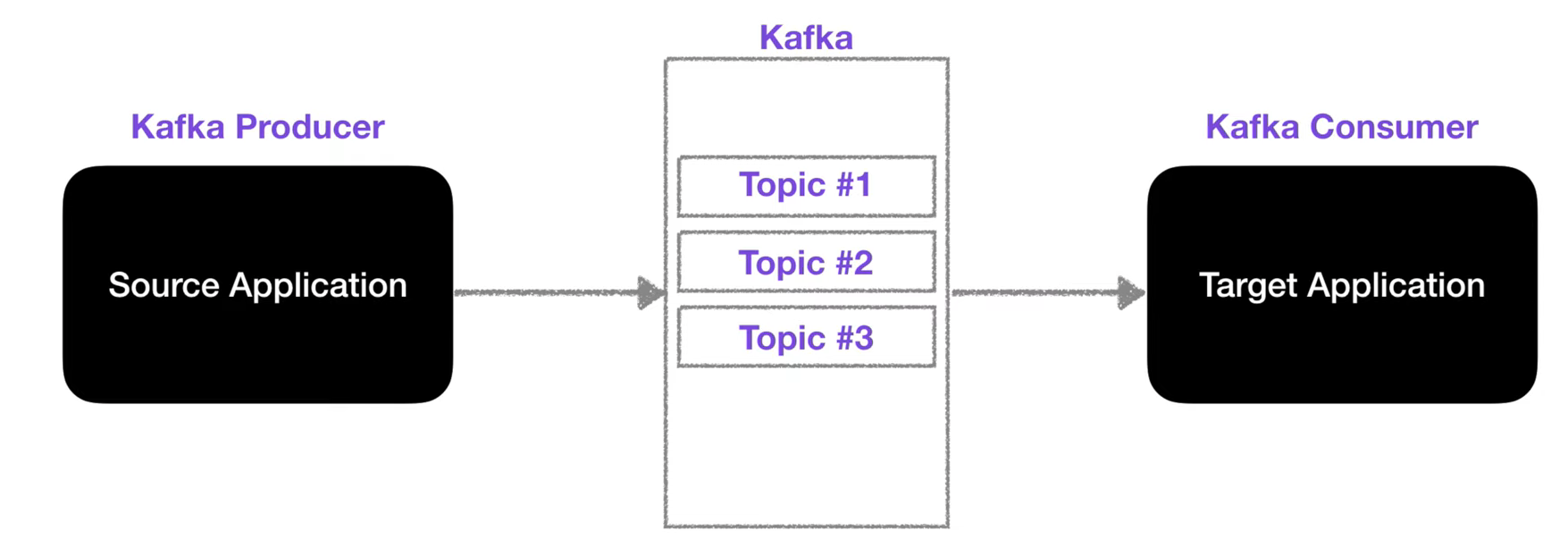
After Kafka
아파치 카프카는 위와같은 복잡함을 해결하기 위해 LinkedIn에서 개발, 오픈소스로 제공
Kafka는 고가용성, 낮은 지연, 높은 처리량이 특징으로 효과적으로 대용량의 테이터를 처리 가능
카프카는 Source Application과 Target Application의 커플링을 약하게 하기 위해 개발됨
Source Apllication은 카프카에 데이터를 전송하면 되고, Target Application은 카프카에서 데이터를 가져오면 됨
- 예를들어 Souce Application은 쇼핑몰의 클릭로그, 은행의 결제로그 등을 보내고,
- Target Application은 로그적재, 로그처리 등의 역할을 할 수 있음
카프카는 각종 데이터를 담는 토픽이라는 개념이 있는데, 큐와 매우 유사함
이 토픽에 데이터를 넣는 역할은 Producer가 하고, 토픽에서 데이터를 가져가는 역할은 Consumer가 함
Producer와 Consumer는 라이브러리도 되어 있어, Application에서 구현 가능