 useok's blog
useok's blog

카프카 컨슈머 애플리케이션
카프카 컨슈머의 동작은 다른 메시징 시스템들과는 다소 다름
다른 메시징 시스템들 같은 경우 컨슈머가 데이터를 가져가면 큐 내부 데이터가 사라지는데, 카프카에서는 컨슈머가 데이터를 가져가더라도 데이터가 사라지지 않음
이와 같은 특징은 카프카, 카프카 컨슈머를 데이터 파이프라인으로 운영하는데 핵심적인 역할을 함
컨슈머의 역할
- Topic의 Partition으로부터 데이터 Polling
- 카프카 컨슈머는 토픽 내부의 파티션에 저장된 데이터를 가져오는데 이를 폴링(polling)이라 함
- Partition offset 위치 기록(commit)
- 오프셋(파티션에 있는 데이터의 번호) 위치 커밋
- Consumer group을 통해 병렬처리
- 컨슈머가 여러개일 경우 병렬처리
JAVA로 작성하는 컨슈머
카프카 클라이언트인 컨슈머와 프로듀서를 사용하기 위해서는 아파치 카프카 라이브러리를 추가해야 함
라이브러리는 gradle이나 maven 같은 라이브러리 관리 도구를 사용하여 편리하게 가져올 수 있음
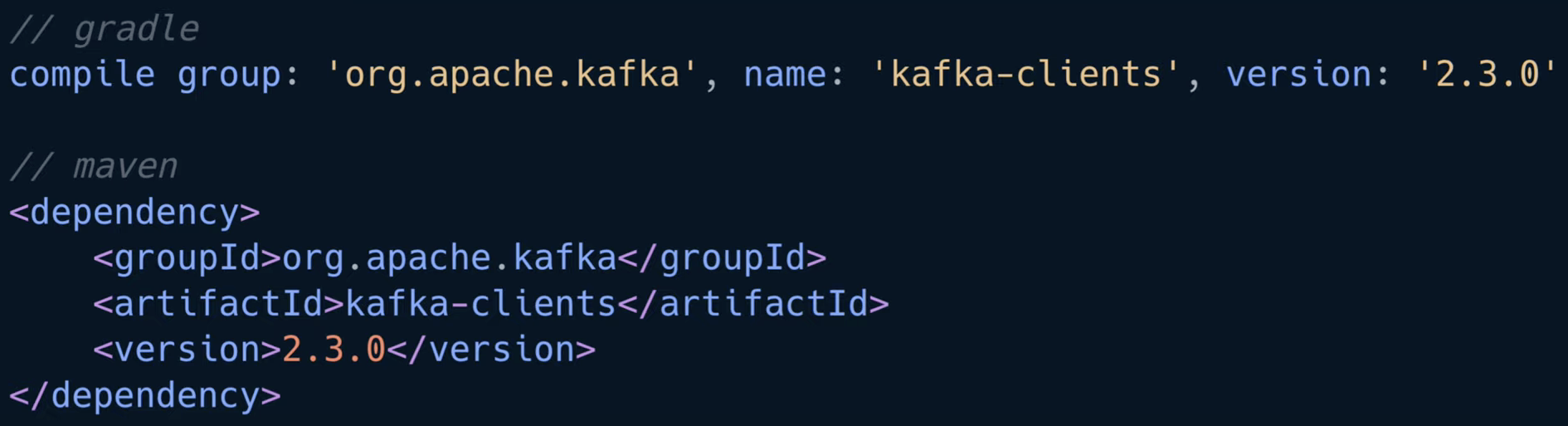
❗ 카프카 클라이언트를 디펜던시로 잡을 때는 버전을 주의해야 함
카프카는 브로커 버전과 클라이언트 버전의 하위호환성이 모든 버전에 대해서 지원하지 않기 때문에 브로커와 클라이언트 버전의 하위호환성을 확인하고 알맞은 카프카 클라이언트 버전을 사용해야 함
예를들어, 특정 버전 카프카 브로커는 특정 버전 카프카 클라이언트를 지원하지 않을 수 있음
카프카 컨슈머를 작성한 코드
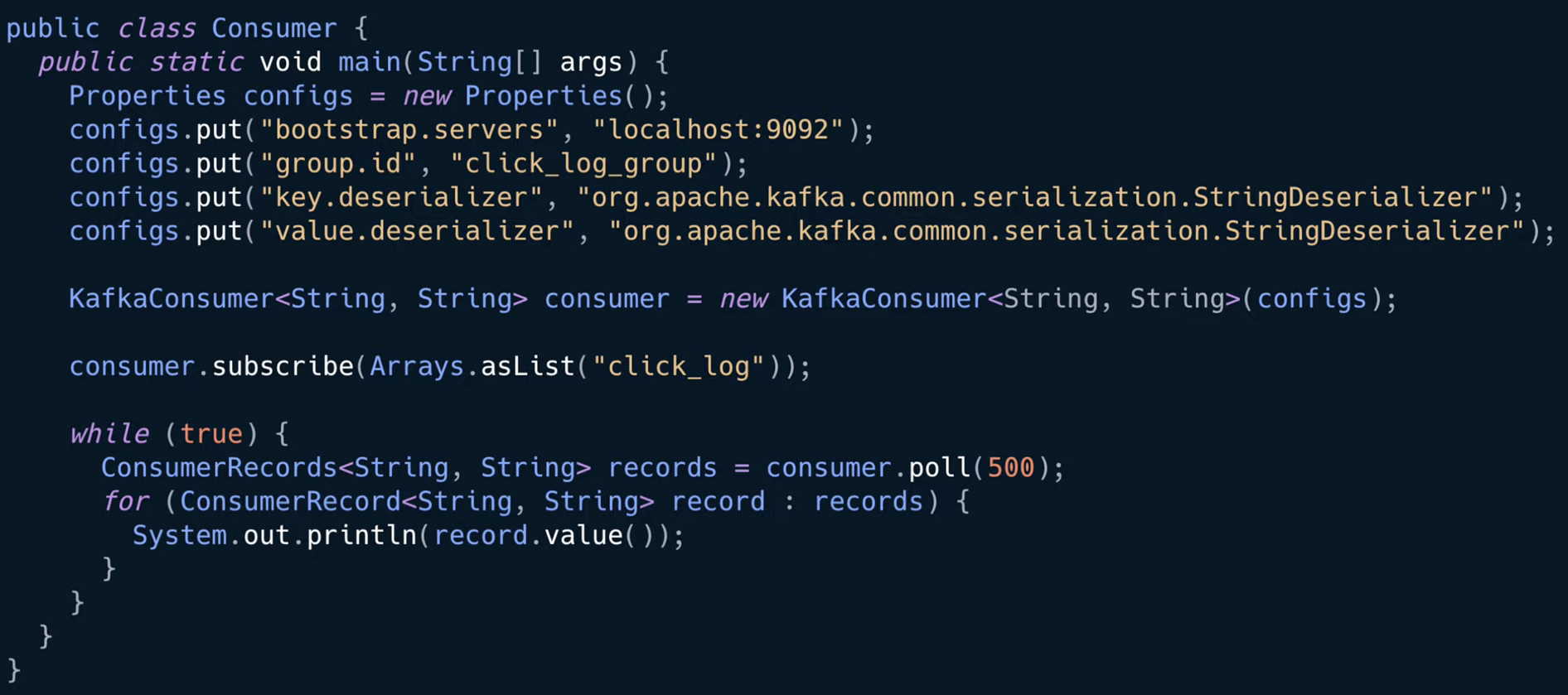
01. 컨슈머 설정
// 자바 프로퍼티 객체를 통해 컨슈머의 설정을 정의
Properties configs = new Properties();
//부트스트랩 서버 옵션을 통해 카프카 브로커를 설정
//부트스트랩 서버 설정을 로컬 호스트의 카프카를 바라보도록 설정함
configs.put("bootstrap.servers", "localhost:9092");
카프카 브로커의 주소목록은 되도록이면 2개 이상의 ip와 port를 설정하도록 권장하는데, 둘 중 한 개 브로커가 비정상일 경우 다른 정상적인 브로커에 연결되어 사용 가능하기 때문
그러므로 실제로 애플리케이션을 카프카와 연동할 때는 반드시 2개 이상의 브로커 정보를 넣는 것을 추천
// 그룹 아이디 지정
configs.put("group.id", "click_log_group");
그룹 아이디는 컨슈머 그룹이라고도 불리는데 컨슈머 그룹은 말 그대로 컨슈머들의 묶음이라고 생각하면 됨
// key와 value에 대해 StringSerializer로 직렬화 설정
configs.put("key.deserializer", "org.apache.kafka.common.serialization.StringSerializer");
configs.put("value.deserializer", "org.apache.kafka.common.serialization.StringSerializer");
02. 컨슈머 인스턴스 생성
//KafkaConsumer 클래스를 통해 이전에 선언한 설정들을 매개변수로 해서 consumer 인스턴스 생성
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(configs);
이 컨슈머 인스턴스를 통해 데이터를 읽고 처리할 수 있음
03. 데이터를 가져올 토픽 지정
// consumer의 subscribe() 메서드를 통해 어느 토픽에서 데이터를 가져올 지 설정
consumer.subscribe(Arrays.asList("click_log"));
만약, 특정 토픽의 전체 파티션이 아니라 일부 파티션의 데이터만 가져오려면
TopicPartition partition0 = new TopicPartition(topicName, 0);
TopicPartition partition1 = new TopicPartition(topicName, 1);
consumer.assign(Arrays.asList(partition0, partition1));
위 코드와 같이 assign() 메서드를 사용
key가 존재하는 데이터라면 이 방식을 통해 데이터의 순서를 보장하는 데이터 처리를 할 수 있음
04. 데이터 가져오기
// 폴링 루프
while (true) {
ConsumerRecords<String, String> records = consumer.poll(500);
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
컨슈머 API의 핵심은 브로커로부터 연속적으로, 그리고 컨슈머가 허락하는 한 많은 데이터를 읽는 것으로 폴링 루프는 컨슈머 API의 핵심 로직이라고 볼 수 있음
컨슈머는 poll() 메서드를 통해 데이터를 가져옴
poll() 메서드에서 설정한 시간(500ms, 0.5초)동안 데이터를 기다리고, 해당 시간동안 데이터가 도착하기를 기다리고 이후 다음 코드 실행
만약 0.5초동안 데이터가 들어오지 않으면 빈값의 records 변수를 반환하고, 데이터가 있다면 데이터가 존재하는 records 값을 반환
records 변수는 데이터 배치로서 레코드의 묶음 list임
그러므로 실제로 카프카에서 데이터를 처리할때는 가장 작은 단위인 record로 나누어 처리하도록 함
for구문 내부에서 record변수의 value() 메서드로 반환된 값이 이전에 producer가 전송한 데이터
위의 코드에서는 폴링루프 구문에서 특정 topic으로부터 가져온 데이터를 출력(println)하기만 했는데, 실제 기업에서는 데이터를 하둡 또는 엘라스틱서치와 같은 저장소에 저장하는 로직을 넣기도 함
그림으로 보는 카프카 컨슈머의 메시지 Polling
01. 2 partitions & 1 consumer
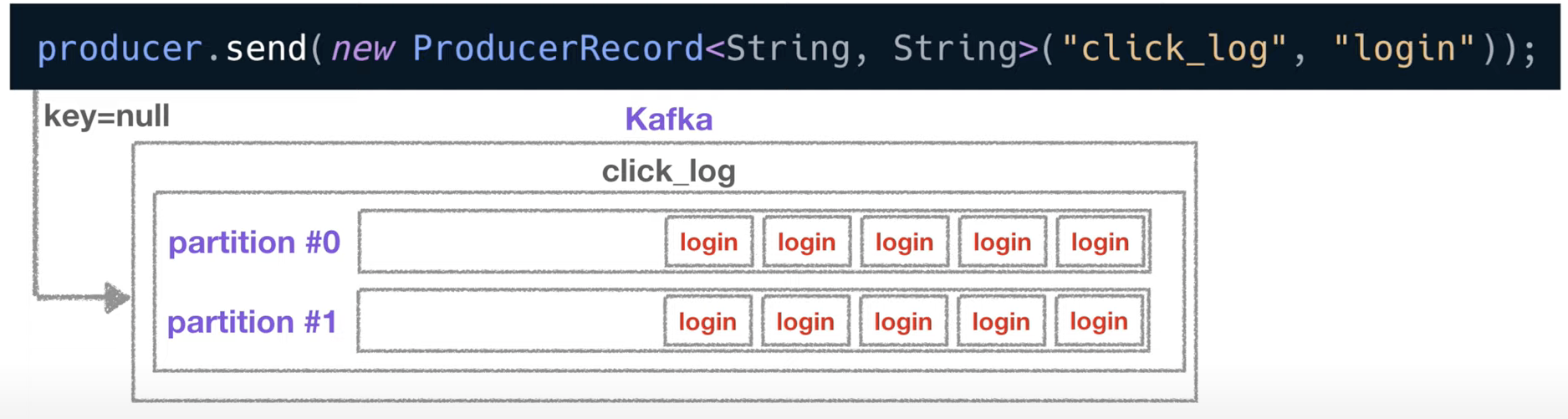
- key가 null일 경우 2개의 파티션에 round-robin으로 데이터를 넣음
- 컨슈머가 하나인 경우 컨슈머 하나가 2개의 파티션에서 데이터를 가져감
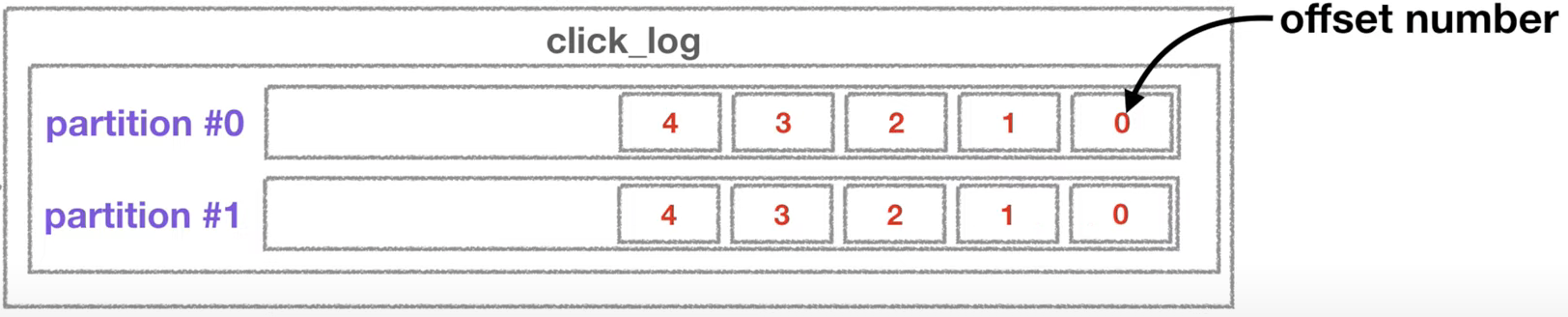
- 이렇게 파티션에 들어간 데이터는 파티션 내에서 고유한 번호를 가지게 되는데 이 번호를 offset이라고 부름
- offset은 토픽별, 파티션별로 별개로 지정됨
- 이 offset이 하는 역할은 컨슈머가 데이터를 어느 지점까지 읽었는지 확인하는 용도로 사용
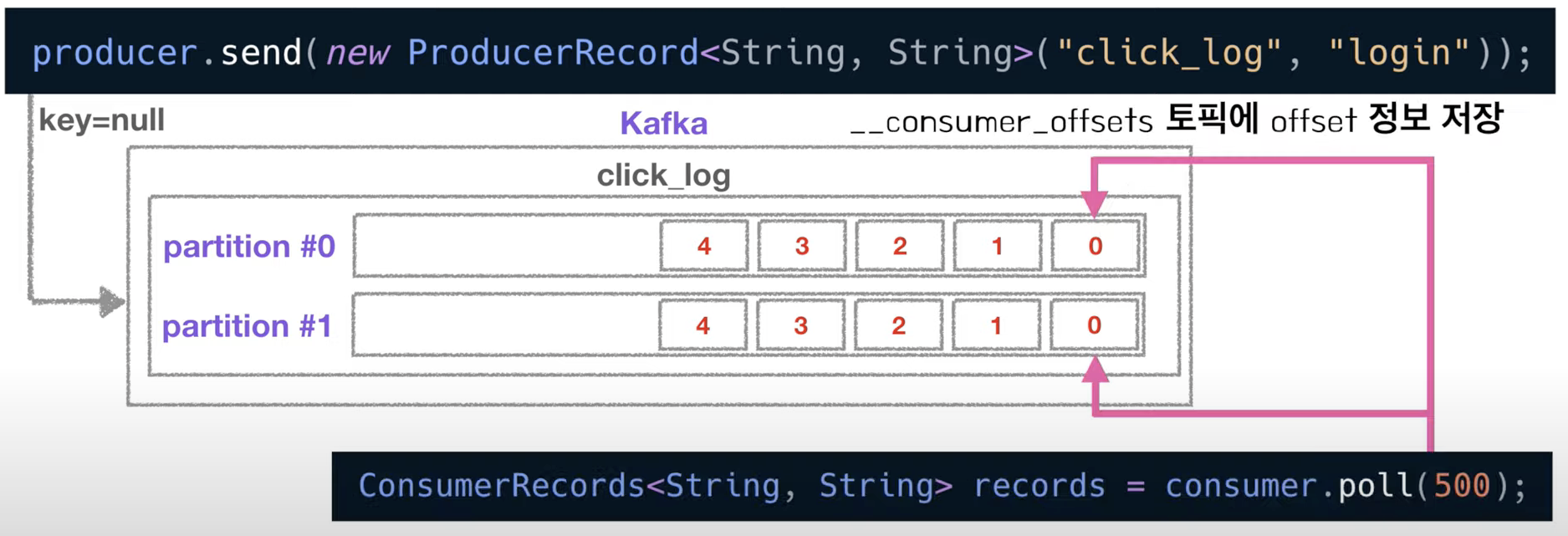
- 컨슈머가 데이터를 읽기 시작하면 offset을 commit하게 되는데, 이렇게 가져간 내용에 대한 정보는 카프카의 __consumer_offset 토픽에 저장
- 컨슈머는 파티션이 2개인 click_log 토픽에서 데이터를 가져갈 때마다 offset정보가 저장됨
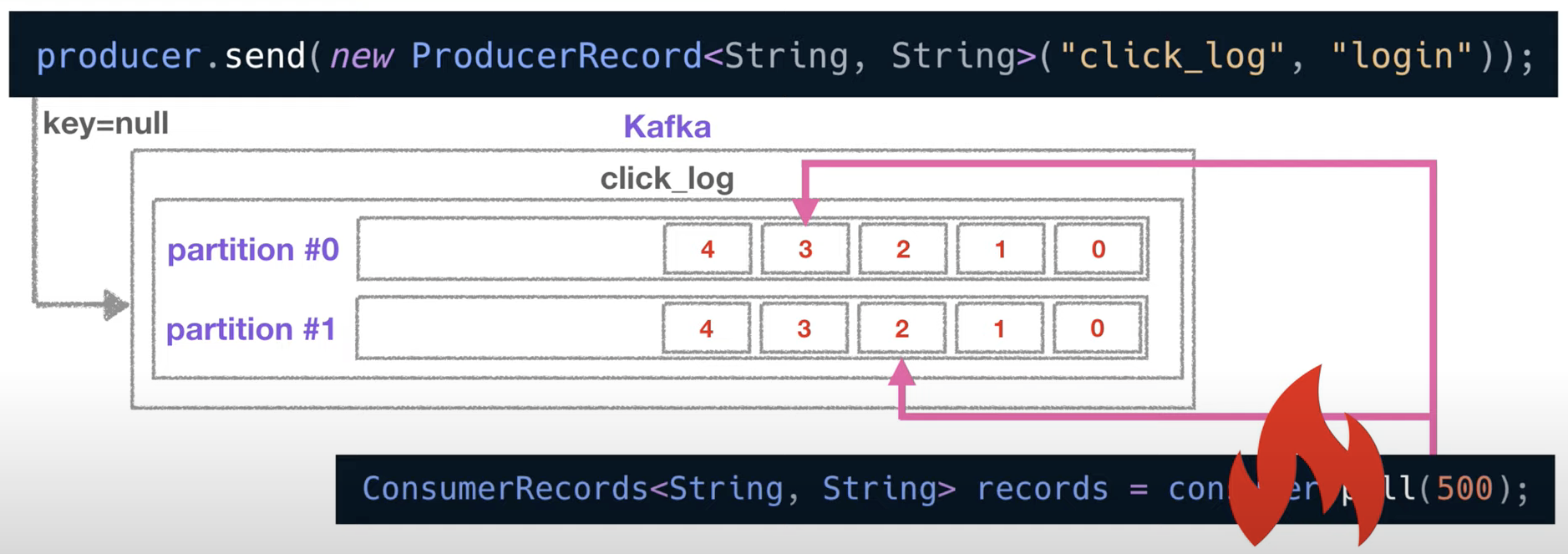
- 컨슈머가 파티션0의 3번 offset까지 읽고 불의의 사고로 실행이 중지되었다고 가정
- 이 컨슈머가 어디까지 읽었는지에 대한 정보는 이미 __consumer_offset에 저장되어 있기 때문에, 이 컨슈머를 재실행 한다면 중지되었던 위치를 알고 있어 시작 위치부터 다시 복구하여 데이터 처리를 할 수 있는 고가용성의 특징을 가짐
02. 2 partitions & 2+ consumers
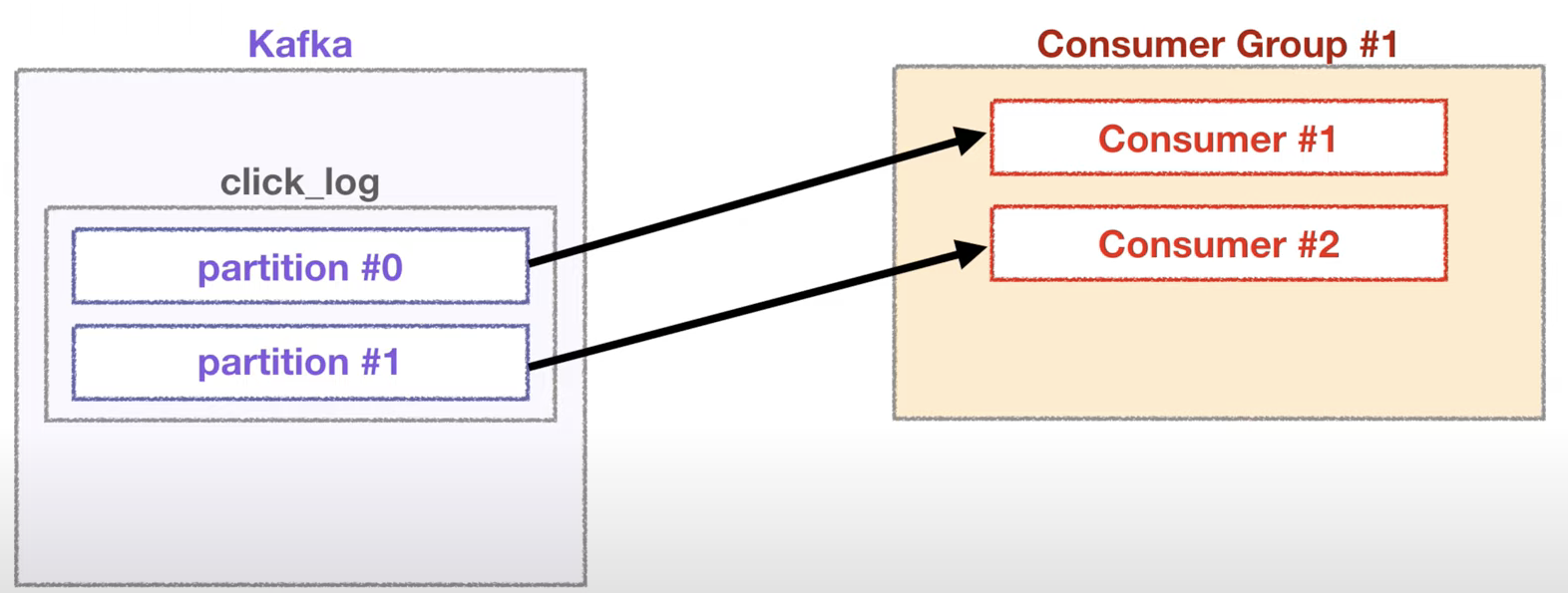
- 2 partitions & 2 consumers
- 2개의 컨슈머로 이루어진 컨슈머 그룹일 경우에는 각 컨슈머가 각각의 파티션을 할당하여 데이터를 가져가서 처리
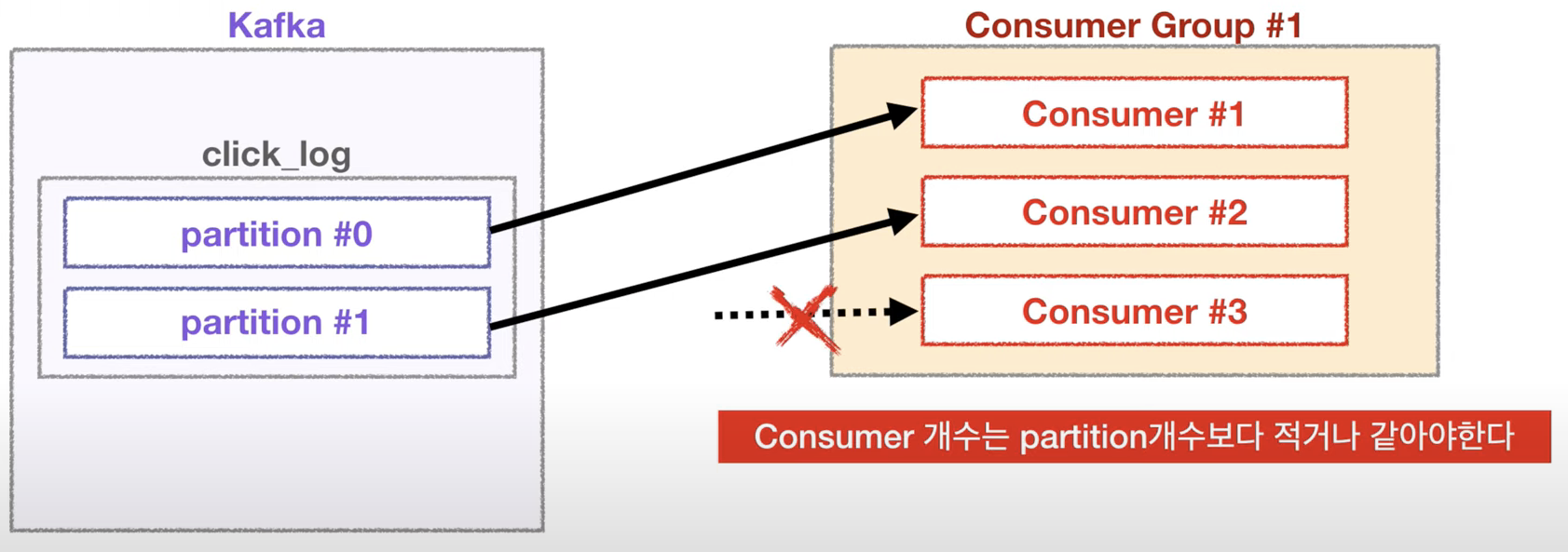
- 2 partitions & 3 consumers
- 3개의 컨슈머로 이루어진 컨슈머 그룹일 경우 이미 파티션들이 각 컨슈머에 할당되었기 때문에 더이상 할당될 파티션이 없어서 동작하지 않음
이와 같이 여러 파티션을 가진 토픽에 대해서 컨슈머를 병렬처리하고 싶다면 반드시 컨슈머를 파티션의 개수보다 같거나 적게 설정
03. 2 partitions & different consumer groups
각기 다른 컨슈머 그룹에 속한 컨슈머들은 다른 컨슈머 그룹에 영향을 미치지 않음
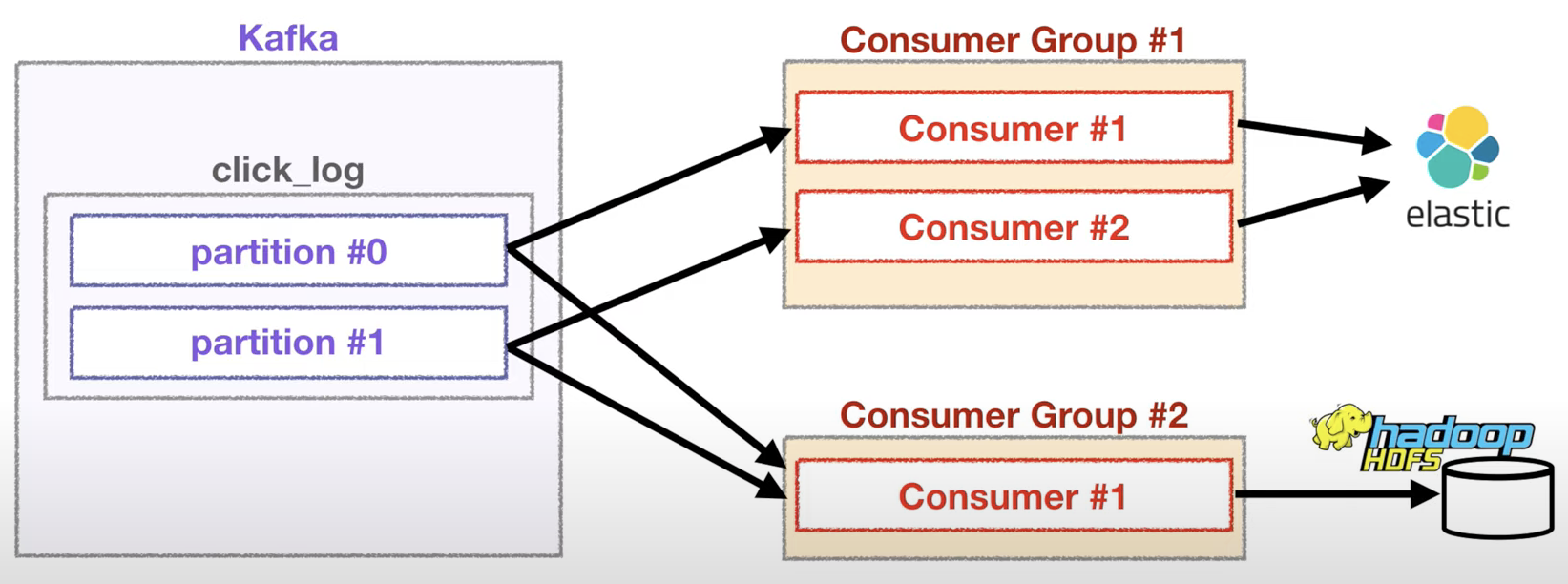
- 데이터 실시간 시각화 및 분석을 위해 ElasticSearch에 데이터를 저장하는 역할을 하는 컨슈머 그룹이 있고, 데이터 백업 용도로 hadoop에 데이터를 저장하는 컨슈머 그룹이 있다고 가정
- 만약 ElasticSearch에 저장하는 컨슈머 그룹이 각 파티션에 특정 offset을 읽고 있어도 hadoop에 저장하는 역할을 하는 컨슈머 그룹이 데이터를 읽는 데 영향을 미치지 않음
- 왜냐하면 __consumer_offset 토픽에는 컨슈머 그룹별로 그리고 토픽별로 oiffset을 나누어 저장하기 때문
- 이러한 카프카의 특징을 토대로 하나의 토픽으로 들어온 데이터는 다양한 역할을 하는 여러 컨슈머들이 각자 원하는 데이터로 처리가 될 수 있음
참고 강의 : https://www.inflearn.com/course/아파치-카프카-입문/dashboard