 useok's blog
useok's blog

AWS에 카프카 클러스터 설치, 실행하기
01. AWS ec2 인스턴스 3개 생성
- 3개의 브로커로 클러스터를 구성할 것이기 때문에 3개의 서버를 사용
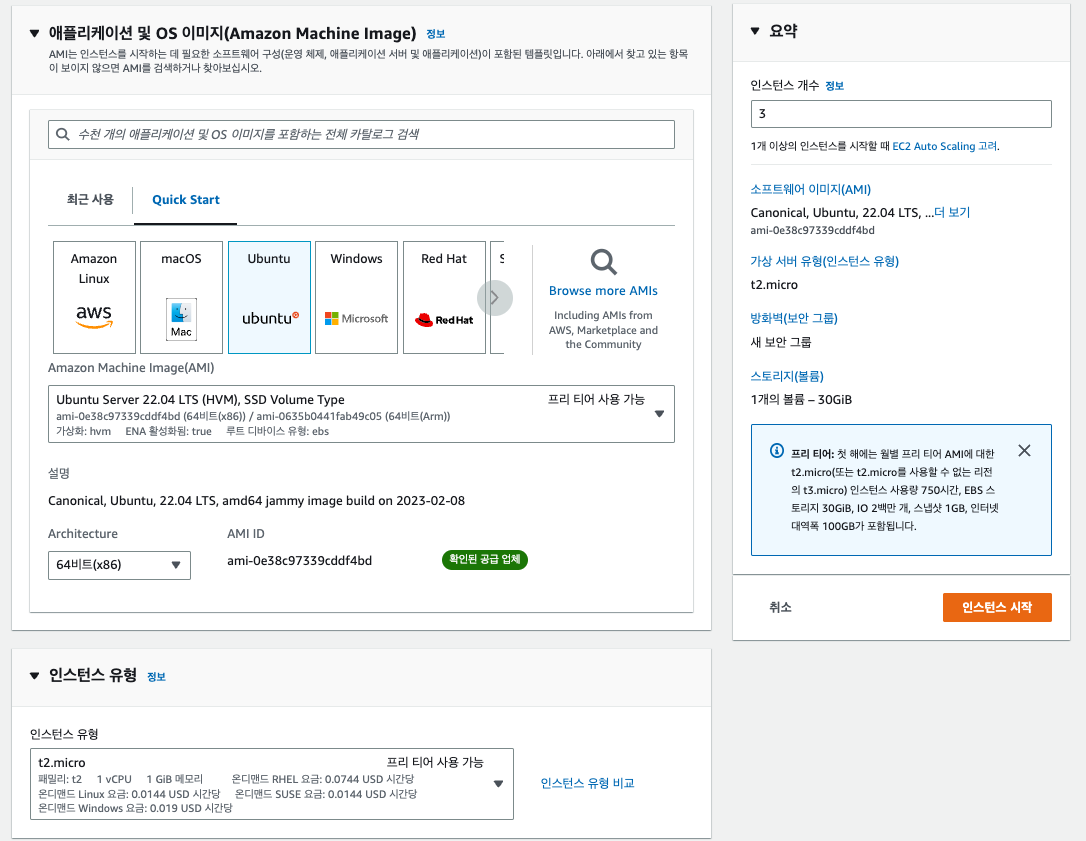
- OS 이미지 : ubuntu 22.04 LTS
- 인스턴스 유형 : t2.micro
02. 각 인스턴스에 인바운드 규칙 추가
AWS 보안그룹에서 아래와 같은 인바운드 규칙 추가

ssh 연결을 위해 22 포트를 사용, 주키퍼는 2181, 2888, 3888 포트를 사용하고, 카프카는 9092 포트를 사용
03. /etc/hosts 파일 수정
편의상 IP 대신 host name(broker01, broker02, broker03)을 사용해 통신하기 위해 /etc/hosts 파일 수정
각각 자기자신의 host는 0.0.0.0으로 작성하고, 나머지는 host ip로 작성
# 만약 broker01인 경우
0.0.0.0 broker01
14.252.123.4 broker02
55.231.124.1 broker03
04. JAVA 설치
sudo apt-get update
sudo apt-get install openjdk-11-jdk
05. zookeeper 설치 / 설정 / 실행
5-1. 각 인스턴스에 zookeeper 설치
# zookeeper 설치
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz
## 압축 해제
tar xvf zookeeper-3.4.12.tar.gz
## 압축 파일 삭제
rm zookeeper-3.4.12.tar.gz
5-2. 각 인스턴스에 생성된 zookeeper 폴더의 conf 파일에서 zoo.cfg 파일 생성
# zoo.cfg 파일 생성
vi zoo.cfg
## configuration 작성
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181
initLimit=20
syncLimit=5
server.1=broker01:2888:3888
server.2=broker02:2888:3888
server.3=broker03:2888:3888
5-3. 각 인스턴스에 생성된 zookeeper 폴더 내부에 myid 파일 생성
- broker01 은 1, broker02는 2, broker03은 3을 작성
# 만약 broker01 인 경우
vi myid
1
cat /home/ubuntu/zookeeper-3.4.12/myid
1
5-4. 각 인스턴스에서 주키퍼 실행
/home/ubuntu/zookeeper-3.4.12/bin/zkServer.sh start

06. 카프카 설치
6-1. 각 인스턴스에 kafka 설치
#kafka 설치
wget https://archive.apache.org/dist/kafka/2.1.0/kafka_2.11-2.1.0.tgz
#압축풀기
tar xvf kafka_2.11-2.1.0.tgz
#압축파일 삭제
rm kafka_2.11-2.1.0.tgz
6-2. 각 인스턴스에 생성된 kafka 폴더의 config 파일에서 server.properties 수정
- server.properties의 초기설정은 broker.id=0 되어있으나, 값을 각자 다른 값으로 설정 ex) 0, 1, 2
- ex) broker01의 broker.id = 0, broker02의 broker.id = 1, broker03의 broker.id = 2
- listeners 주석 해제
- advertised.listeners 주석 해제후, 값을 PLAINTEXT://broker01:9092 로 변경
- 각 인스턴스에 있는 브로커 이름을 각각 기입
- zookeeper.connect 의 값을 broker01:2181,broker02:2181,broker03:2181/test 로 변경
- 마지막에 /test 와 같이 route를 넣는 것을 추천. 이렇게 넣을 경우 zookeeper의 root node가 아닌 child node에 카프카정보를 저장하게 되므로 유지보수에 이득이 있음
vi server.properties
broker.id=0 #broker01 인 경우 0을 값으로 넣었고, broker02는 1, broker03은 2를 넣어줌
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://broker01:9092 #각 인스턴스에 있는 브로커 이름을 각각 기입
zookeeper.connect=broker01:2181,broker02:2181,broker03:2181/test
6-3. 각 인스턴스에서 카프카 실행
./bin/kafka-server-start.sh config/server.properties
❗ 카프카를 실행했을때
OpenJDK 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c0000000, 1073741824, 0) failed; error='Not enough space' (errno=12)
위 오류가 발생한다면, 이는 kafka-server-start.sh에서 등록되어 있는 최초 java heap memory size 때문인데, kafka-server-start.sh 파일에서
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
위 세 줄을 각각 주석(#) 처리하거나 1G 보다 더 낮춰서 다시 실행
07. console-producer, console-consumer 테스트
카프카가 실행된 상태에서 세 인스턴스 중 임의의 인스턴스에 추가로 ssh 접속해 토픽을 생성후, producer와 consumer가 정상적으로 동작하는지 확인
cd kafka_2.11-2.1.0
## test_topic 생성
./bin/kafka-topics.sh --create --zookeeper broker01:2181,broker02:2181,broker03:2181/test --replication-factor 3 --partitions 1 --topic test_topic
# console-producer
./bin/kafka-console-producer.sh --broker-list broker01:9092,broker02:9092,broker03:9092 --topic test_topic
## console-consumer
./bin/kafka-console-consumer.sh --bootstrap-server broker01:9092,broker02:9092,broker03:9092 --topic test_topic --from-beginning
topic에 console-producer로 데이터를 입력해 넣으면

console-consumer에서 데이터를 확인 가능

(위 사진엔 --topic test 라고 나와있는데, --topic test_topic 이 맞음. 귀찮아서 사진 교체 안 한 것도 맞음)
참고 강의 : https://www.inflearn.com/course/아파치-카프카-입문/dashboard